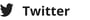
This is the fourth article in our mini-series, which aims to showcase the evolution of Data extraction solutions over the past 2 to 3 years. These articles highlight the advancements made in recent months and illustrate what is now possible. The most significant improvement is the ability of current solutions to learn autonomously.
If you missed the introduction to this mini-series, you would find it here: Mini-series: The real power of new data extraction strategies. The previous article discussed how modern solutions could effectively handle repetitions on handwritten documents: Use Case 3 - Handling Repetitions.
Could you please sort your groceries before I scan them?
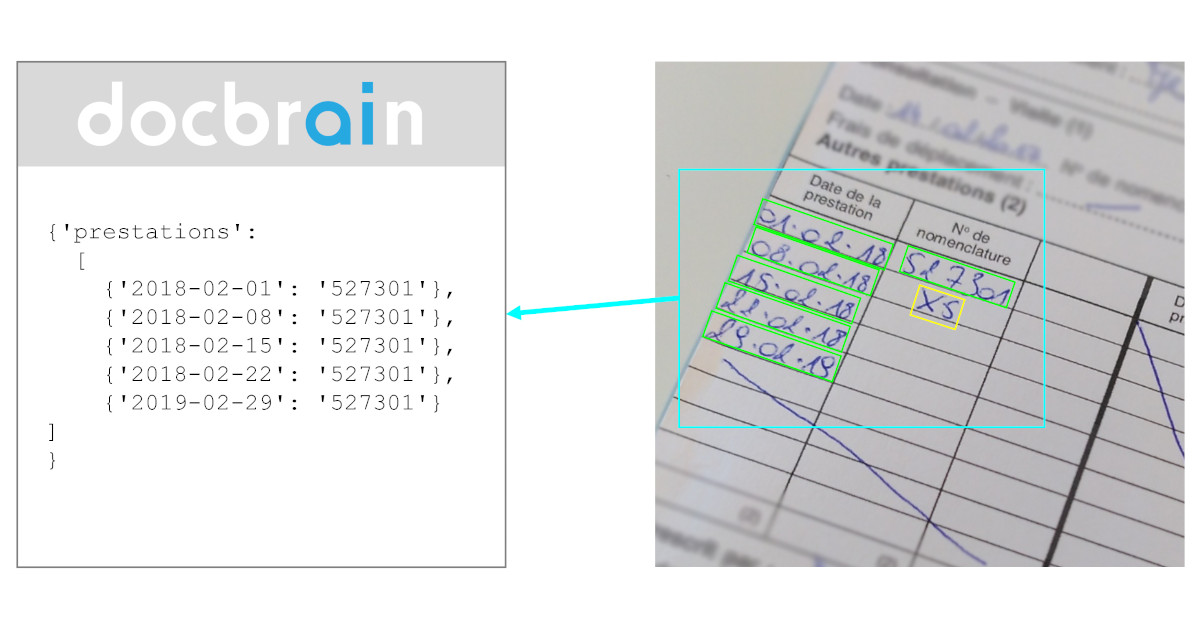
When you go shopping, purchasing the same item multiple times is not uncommon. Most probably, you drop your groceries in random order on the conveyor belt. As a result, these items will appear on the receipt in the order they were scanned. As a consumer, this has no consequence and probably no interest. However, for companies extracting data from receipts, these details matter. These companies are typically interested in knowing what you buy, in what quantity, and at what frequency. Grouping identical items is a fundamental part of their analysis.
The Challenges in Grouping similar items.
Usually, their software employs Optical Character Recognition (OCR) to extract the text from the documents. In the second step, the extracted sequence of characters is searched for the specific items you purchased. Finally, if the items are extracted accurately, they are grouped. However, identifying multiple identical items has been a challenging task. Character recognition errors in item descriptions or codes have made this task more difficult than it should be. As a result, either grouping is not possible, or significant effort is required to achieve it.
The benefits of new-generation models
On the other hand, new-generation models can identify similar items and extract them only once. At first glance, this may seem like a minor difference in the process, but it has significant consequences. The probability of errors in the item description, code, or price is substantially reduced by extracting the data only once.
For example, consider a receipt with the following items:
BANANAS 000000004011 0.95
STRWBRY 076471782200 4.35
BEVERAGE 003120002133 2.00
BANANAS 000000004011 0.95
HAND CLEANER 004125100005 1.67
BANANAS 000000004011 0.95
BEVERAGE 003120002133 2.00
SNACK BARS 002190848816 4.98
BEVERAGE 003120002133 2.00
AVOCADO 000000004046 0.99
BEVERAGE 003120002133 2.00
Our model would output the following:
[{'item': 'BANANAS', 'qty': 3, 'code': '000000004011', 'price': 0.95},
{'item': 'BEVERAGE', 'qty': 4, 'code': '003120002133', 'price': 2.00},
{'item': 'STRWBRY', 'qty': 1, 'code': '076471782200', 'price': 4.35},
{'item': 'HAND CLEANER', 'qty': 1, 'code': '004125100005', 'price': 1.67},
{'item': 'SNACK BARS', 'qty': 1, 'code': '002190848816', 'price': 4.98},
{'item': 'AVOCADO', 'qty': 1, 'code': '000000004046', 'price': 0.99}]
The impact of additional steps in the workflow on errors, costs, and delays
The "intelligence" – if we can call it that way - of these models eliminates the need for pre- or post-processing steps. While it may not seem like a significant breakthrough, in practice, every additional step in the workflow introduces the possibility of errors. In document processing, software errors require manual verification, incurring costs and delays. Moreover, it also involves code development. This code needs to be maintained and is typically barely flexible, requiring extensions or partial rewrites when the input changes, such as when dealing with receipts from a new supermarket chain. This creates additional development and maintenance costs for these companies.
These new models are already available. Don’t wait to reduce costs.
If you would like to learn more about these new models, please get in touch with us. We would be delighted to provide you with further information. And if you need more to be convinced, check out the other articles in this series. The following example showcases how these new solutions consider all available visual information on a document to make informed decisions, not just relying on characters only. You'll find it here: Use Case 5 - Logo Recognition on Invoices.