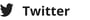Applying to universities or high schools can feel like an overwhelming task, with the need to submit various documents, including academic records, recommendation letters, personal statements, and standardised test scores. Admissions teams face significant challenges, especially in large universities where thousands of students apply yearly. Processing these documents manually has been difficult due to their diverse formats and layouts. However, Artificial Intelligence (AI) has ushered in new possibilities, enabling institutions to automate parts of the process through AI document processing. This blog article will explore the importance of application documents, the obstacles admissions teams face, and how AI can revolutionise their operations, making the journey smoother for all.

This is the final article in our five-part series highlighting the advancements in data extraction solutions over the past two years. Through this series, we aim to demonstrate the progress made in recent months and showcase the capabilities that were previously unavailable. The most notable improvement lies in the ability of current solutions to learn autonomously.
This is the fourth article in our mini-series, which aims to showcase the evolution of Data extraction solutions over the past 2 to 3 years. These articles highlight the advancements made in recent months and illustrate what is now possible. The most significant improvement is the ability of current solutions to learn autonomously.
If you missed the introduction to this mini-series, you would find it here: Mini-series: The real power of new data extraction strategies. The previous article discussed how modern solutions could effectively handle repetitions on handwritten documents: Use Case 3 - Handling Repetitions.
Could you please sort your groceries before I scan them?
When you go shopping, purchasing the same item multiple times is not uncommon. Most probably, you drop your groceries in random order on the conveyor belt. As a result, these items will appear on the receipt in the order they were scanned. As a consumer, this has no consequence and probably no interest. However, for companies extracting data from receipts, these details matter. These companies are typically interested in knowing what you buy, in what quantity, and at what frequency. Grouping identical items is a fundamental part of their analysis.
Welcome to the third article of our mini-series on the recent evolution of data extraction solutions. This series aims to showcase the advancements made in the field over the past 2 to 3 years. This article will discuss one of the most remarkable improvements in recent data extraction solutions - their ability to learn autonomously.

Data extraction solutions have advanced significantly in the last 2 to 3 years, allowing us to do things today that were impossible just a few months ago. One of the most notable improvements is the ability of these recent solutions to understand the context of a document.
If you missed this mini-series introduction, you can find it here: Mini-series: the real power of new data extraction solutions.. In the previous article, we discussed how to handle date formats, which you can access here: Smart Date Formatting.
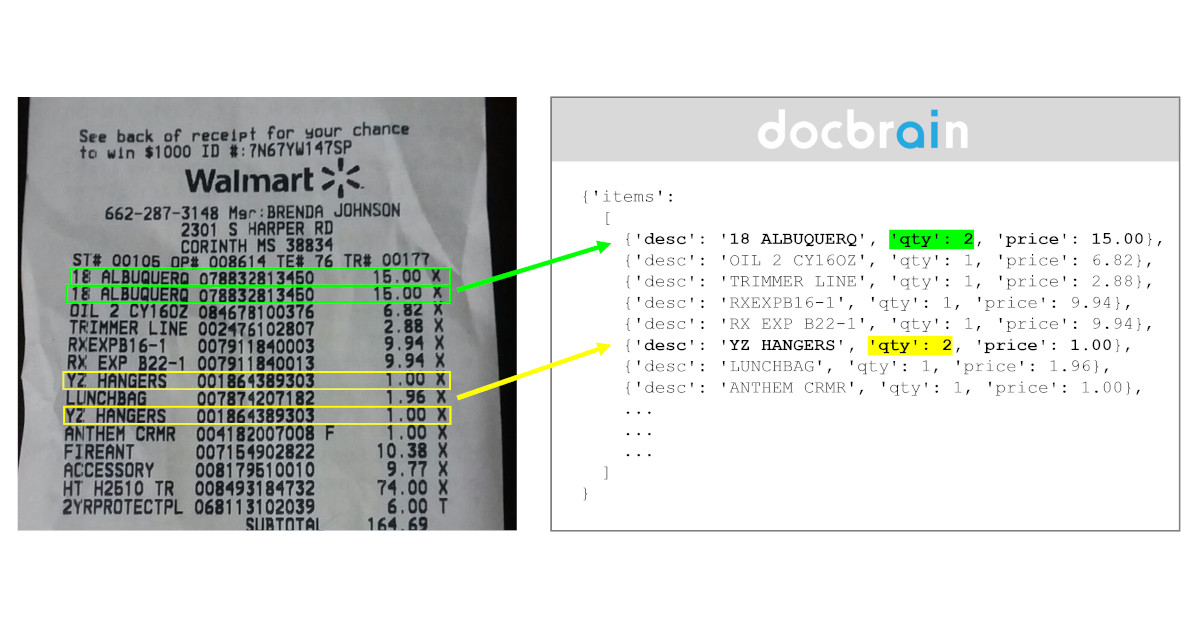
This second article will explore another real-world use case: ditto marks.
What are Ditto marks?
You may be wondering what a ditto mark is, but chances are, you already know it, not by that name. A ditto mark is a double quote character that indicates that the word or value above it should be repeated. It is commonly used in handwritten documents where the precious “copy-paste” does not exist.
Let's look at an example. When listing items o

In this article, we kickstart a mini-series of five that focuses on the vast improvements seen in data extraction over the past few years. We'll explore how new solutions have revolutionized the process by examining real-world examples. This first article explores how extracting dates from documents has become more accessible and efficient, even with various date formats. If you missed the introduction to this mini-series, you'll find it here: the real power of the new data extraction models.

Over the past two years, the field of Artificial Intelligence (AI) has been advancing at an incredible pace. While much attention has been given to large language models like ChatGPT, there have also been considerable advancements in document processing. These advancements have brought us new solutions that deliver impressive improvements in data extraction. We are now entering an era of information extraction, more than data extraction.
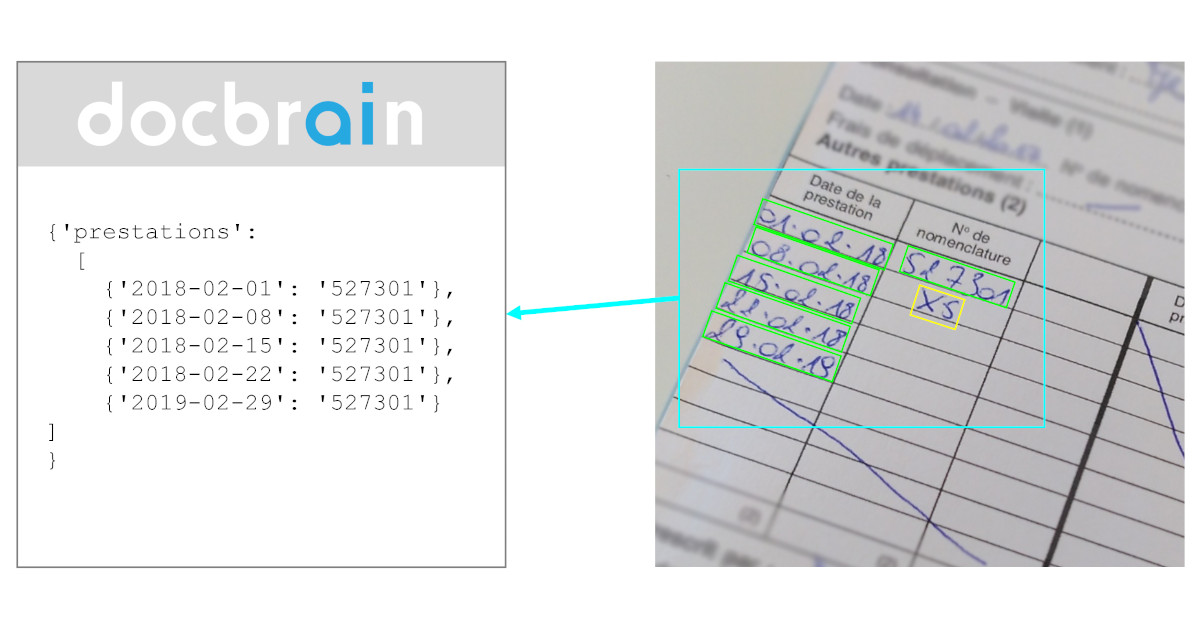
Effective management of technical documents is crucial for the smooth operation, efficiency, and responsiveness of industrial companies. The quality and availability of information within these documents directly impact the performance of operations, maintenance, and engineering teams. However, managing technical documents has always been a complex and resource-intensive task. Fortunately, with the recent advancements in AI algorithms, a new era in technical document management has emerged, offering higher data quality, faster access to information, and ultimately, more efficient operations and robust internal processes.

Ending the series on AI-enabled process automation, Moonoia is honored to have ECM expert Zbigniew Smierzchala as guest writer. Zbigniew has 25 years of experience with content capture concepts and technologies (software and hardware). He worked in ECM context in sales, business development and product management roles for Kodak Eastman Software, EASY Software, Xerox and Hewlett-Packard.

Continuing our special blog series on the current state of AI-enabled process automation, Moonoia is honored to have ECM expert Zbigniew Smierzchala as guest writer. Zbigniew has 25 years of experience with content capture concepts and technologies (software and hardware). He worked in ECM context in sales, business development and product management roles for Kodak Eastman Software, EASY Software, Xerox and Hewlett-Packard.