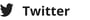
Welcome to the third article of our mini-series on the recent evolution of data extraction solutions. This series aims to showcase the advancements made in the field over the past 2 to 3 years. This article will discuss one of the most remarkable improvements in recent data extraction solutions - their ability to learn autonomously.
If you missed the introduction to this mini-series, you could catch up by following this link: Mini-series - The real power of new data extraction solutions. Additionally, the previous article delves into how recent solutions address the challenges posed by ditto marks in handwritten documents: Use Case 2 - Handling Ditto Marks.
The Challenge of Repetitions in Handwriting
When it comes to handwriting, efficiency is vital. People often look for ways to write less while conveying the necessary information. However, while this may save time for the writer, it presents a challenge for OCR (Optical Character Recognition) models used for data extraction.
In the previous article, we've seen how ditto marks are widely used in handwriting. Here we'll see another typical example of something so easy for humans and so challenging for computers.
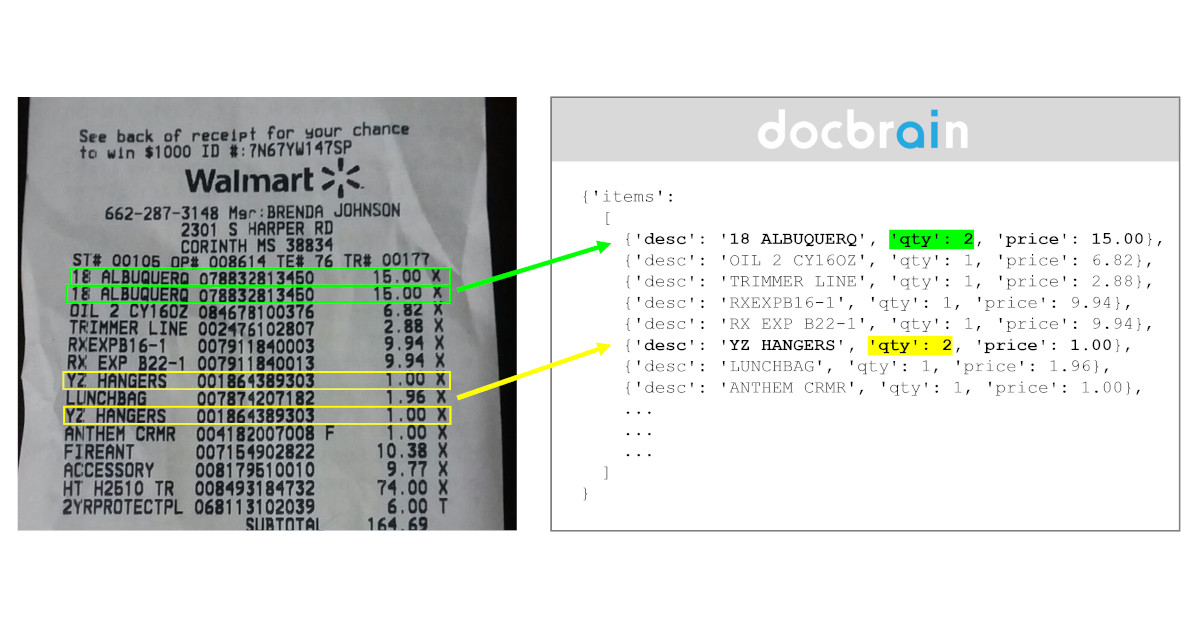
One common technique medical practitioners employ is writing a line of information and indicating "x2" or "x5" next to it to signify that the information should be repeated 2 or 5 times. Traditional OCR solutions can sometimes extract these repetition characters properly but are for sure not able to understand what data needs to be repeated.
How Traditional OCR Struggle with Repetition Indicators
Understanding the scope of the information to be repeated becomes a complex task for software. Does it involve the entire line or only specific elements? What is it supposed to do if the following lines already contain information?
The OCR output would only provide the "x2" or "x5" statement without understanding the underlying context. Consequently, as with the others, these statements often ended up in the manual processing queue.
The Magic of New Data Extraction Models
Recent data extraction models, however, have the magical ability to comprehend and generate information hidden by these seemingly innocent statements. How do they achieve this? It's not a simple explanation, but in essence, these models analyze more than just the characters present in a document. They consider the layout and context, recognizing patterns rather than focusing on individual characters.
To illustrate, let's consider the following example:
01-02-2023 Follow-up check x4
01-03-2023
01-04-2023
01-05-2023
Our model outputs the following:
{[
{'2023-02-01': 'Follow-up Check'},
{'2023-03-01': 'Follow-up Check'},
{'2023-04-01': 'Follow-up Check'},
{'2023-05-01': 'Follow-up Check'}
]}
Analysing Layout and Context: The Key to Understanding Hidden Information
This example illustrates how recent data extraction solutions possess a reasonable level of "intelligence." They start understanding how humans work. They can deduce information that is not explicitly visible in the document itself. This intelligence significantly reduces manual processing time and faster overall processing.
If you need to see more, check the next article. It goes about grouping similar items on-the-fly: Use Case 4 - Grouping Duplicates.
Do you think these models could turn your data extraction process into an information extraction process? Please contact us. Our team will be delighted to prepare a tailored solution that meets your needs.