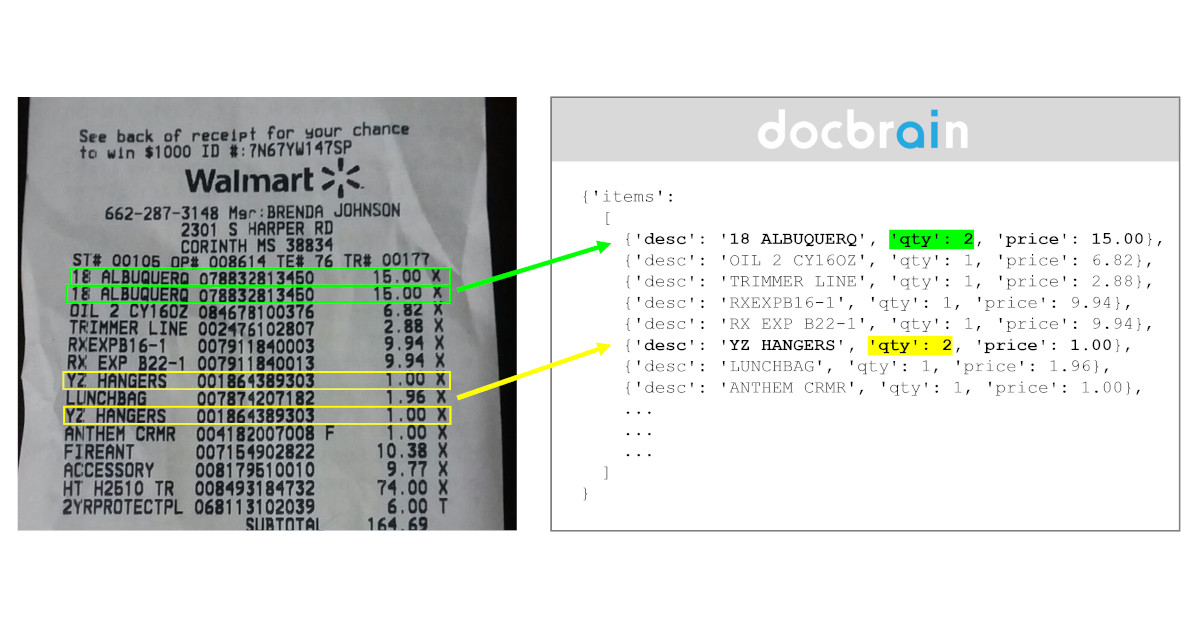
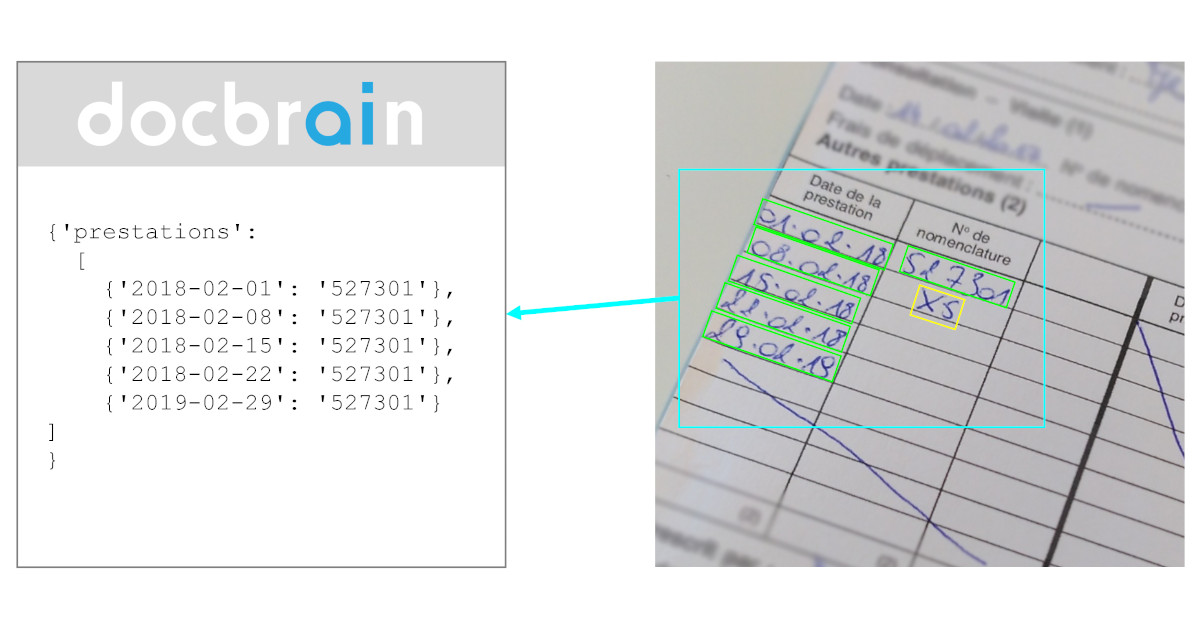
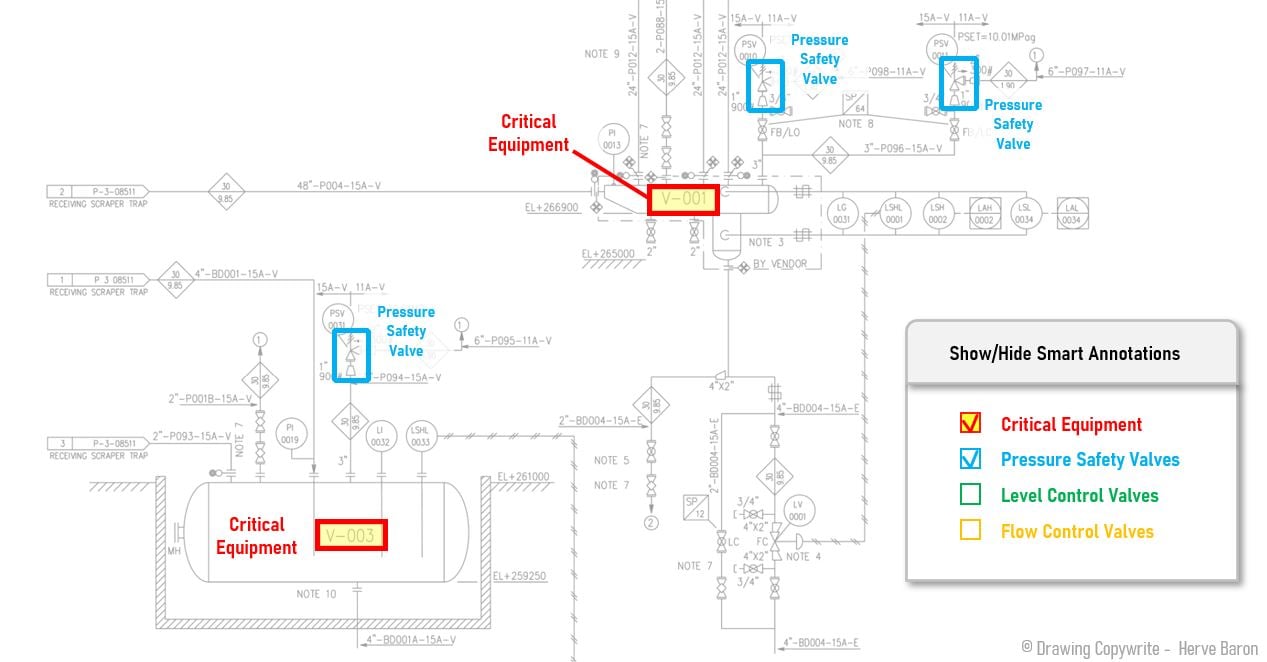
In this article, we kickstart a mini-series of five that focuses on the vast improvements seen in data extraction over the past few years. We'll explore how new solutions have revolutionized the process by examining real-world examples. This first article explores how extracting dates from documents has become more accessible and efficient, even with various date formats. If you missed the introduction to this mini-series, you'll find it here: the real power of the new data extraction models.
The Challenge of Extracting Dates
Dates hold vital information. Whether it's an invoice due date, a contract start- or end date, or a patient care date, accurately extracting them is of utmost importance. Failure to do so can lead to significant issues in the downstream process. Despite their crucial role, they suffer from the various format they can take. Indeed, date formats can vary depending on the document type and the region it originates from.
Legacy Solutions and their Limitations
Traditional solutions involved extracting the text from documents and subsequently identifying sequences of characters as dates. These dates were then converted into a unified format for further processing.
Unfortunately, these tools do not understand what constitutes a date and cannot manage their format. This requires developers to do the job. To complete their task with reasonable effort, they need to know a priori where the date will be located and what format it will take. Consequently, the code had to be tailored for each document individually, resulting in tedious and expensive development, testing, and maintenance processes.
Embracing Smarter Models
Fortunately, recent data extraction models are much more “intelligent.” They can leverage visual cues in the document and analyze the data's context. Armed with contextual awareness, these models possess a - kind of - understanding of what a date is and how to interpret it correctly. As a result, they can output the date in any desired format, providing flexibility and robustness to your process.
A Case Study: The Belgian ID Cards Example
Belgian ID Cards contain three critical dates: 'date of birth,' 'valid from,' and 'valid until.' The 'date of birth' employs the 'DD MMM YYYY' format, while the others follow 'dd.mm.yyyy.' Since ID Cards are standardized, one might assume extracting these dates would be straightforward. However, complications arise when users provide scanned or quickly photographed copies of their cards. Each user's document can vary significantly in quality, orientation, and card position.
Adapting to Any Situation
Modern data extraction models excel in these situations. Regardless of the image's orientation or the card's position on the document, these models can seamlessly extract and convert the dates in a single step. Consequently, pre-processing to align the ID card with the page or post-processing steps to reconstruct date sequences are unnecessary. The new models simplify the process, achieving the same results as their legacy counterparts but with superior speed, accuracy, and reduced coding effort.
Benefits and Cost Savings
For organisations processing thousands of official documents annually — such as ID Cards, passports, driving licenses, or insurance cards — embracing these advanced data extraction solutions can drastically reduce processing costs. Deploying these new models is faster and more cost-effective than ever before. What once took months of labour can now be accomplished in days or weeks.
In the next article, you'll discover how these new solutions can handle Ditto Marks. If you don't know what is a Ditto Mark, don't wait: Use Case 2 - Handling Ditto Marks.
If you are eager to optimise your document processing workflow, please get in touch with us. We will be delighted to demonstrate how your processes can be upgraded with these cutting-edge solutions.