Continuing our special blog series on the current state of AI-enabled process automation, Moonoia is honored to have ECM expert Zbigniew Smierzchala as guest writer. Zbigniew has 25 years of experience with content capture concepts and technologies (software and hardware). He worked in ECM context in sales, business development and product management roles for Kodak Eastman Software, EASY Software, Xerox and Hewlett-Packard.
In the previous article, we proposed the following equation to describe the “hyperautomation” components:
Hyperautomation = (Process Mining + Business Process Management + Robotic Automation + X1 + X2 + … + Xn) * Machine Learning
…where “X“ represents any additional technology required to extend the range and sophistication of process - automation.
Content Capture is one of these X’s, playing a critical role in process automation, offering customers capabilities that go beyond simple task (or desktop) automation. Using a car analogy, if the “hyperautomation” were a car, RPA were an engine and data were the fuel. Typically the bots (RPA) can check CRM master data, create Purchase Requisition from Excel, create Sales Inquiry in SAP as well as automate many other repetitive and time-consuming tasks.[1] Such simple automation can deal ideally with structured data and simple tasks, however, while it is true that practically most documents are today digitally-born, 80% of enterprise data is unstructured and we are producing more unstructured data than ever before.
{{cta('322f1828-efa6-4a3d-9863-0aa6c38eb9d0')}}
Content capture can transform the unstructured data into the compatible “fuel” for the RPA “engine”, enabling automation to expand to more complex processes relying on unstructured data input.

Figure 1: Fueling the automation with data (car analogy)
How difficult it is to achieve data standardization and friction-less data exchange shows the recent report released by EU on implementation of the Directive 2014/55/EU on eInvoicing in public procurement. According to the report, some countries requested a "year of extension", meaning a legal deadline of 18 April 2020 for eInvoicing implementation at the local and regional levels. Today, according to latest country factsheet, only thirteen countries are fully or partially compliant with the Directive.
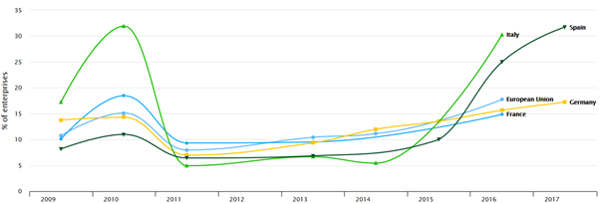
Figure 2: Enterprises sending e-invoices (derived indicator) in 4 largest EU countries, without financial sector
The indicator refers to sending invoices in an agreed standard format (as EDIFACT, XML, etc) which allows their automatic processing, without the individual message being manually typed. Source: EU Digital Scoreboard.
This recent AIIM survey shows that paper e.g. “analogue data carrier” is also prevailing in business processes.
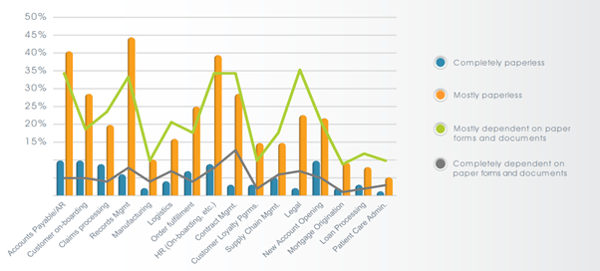
Figure 3: State of Document-oriented Processes − Describe how dependent each of the following process are on paper forms and documents. (Source: AIIM)
The resilience of paper as a “data carrier” can by generally explained by people and processes-related root causes, such as:
- Preference for paper: tangibility, trust, retention
- Lack of priority for projects targeting paper elimination
- Lack understanding of paper-free options
- Inertia - Paper processes work
From a technology standpoint, the key challenges are:
- Lack of interoperability - difficulty to exchange data between different systems
- Difficulty to handle different content formats
- Lack of standard solution or common framework to facilitate adoption
With the progressing democratization of personal (mobile) technology, social media, chat bots, augmented reality and a whole new generation of “always connected” customers, everything today can be a source of data that needs to be captured. Images coming in via mobile, with smartphones being the new scanners, pose new challenges due to lack of standardization at input level. There is almost no control over the images, which makes the pre-processing stage unnecessarily cumbersome. Moreover, multi-page document packages are being received in bulk and manual labor teams are putting in considerable time and effort just to split these packages or just to distinguish between the different documents appearing on a single image file. Additionally, the inability to extract handwriting from documents (or any image-based file, for that matter) was still the greatest weakness for capture in 2019, as reported by AIIM.
Traditional OCR does not yield acceptable results in these new conditions, triggering too much manual exception-handling for a process to be automated end-to-end. Moreover, “one-size-fits-all” capture solutions have always had limited applicability.
Utilizing machine learning to extract, classify, label and validate data, AI-enabled capture solutions succeed where traditional capture is failing – at yielding high accuracy at acceptable pass rates from unstructured or semi-structured sources while remaining scalable, efficient and – very importantly – adaptable, reusable and self-improving. The aim is to increase the amount of the data extracted and the accuracy of that data at the same time, but also to maintain performance over time and transfer the acquired knowledge to new similar projects.
AI-enabled capture does not need templates, dictionaries or taxonomies and it can very well be alphabet-agnostic just as it is language-agnostic. Data sources have multiplied so much that it’s impossible to imagine there will be any less variance in document-centric processes from now on, so spending time and money on creating new templates is not justifiable anymore.
Leveraging AI-enabled capture to expand automation projects to content processing is possible as advanced capture has come a long way from the original “scan-to-archive” to the more integrated, intelligent “scan-to-process”. Transactions and decisions are triggered automatically based on the understanding of the content being extracted.
Finally, it is important to understand that intelligence is not something you plug and play. AI needs retraining as performance diminishes over time, so these are costs to be taken into consideration at the onset of the project. Actually, all AI projects should include a separate dedicated chapter where future retraining is discussed.
Machine learning-enabled capture, data extraction, validation, entity extraction, analysis and so on improve the quality of the data fueling the processes
There is no doubt that AI-powered capture, extraction, validation and analysis enhance value for RPA solutions across the enterprise. However, according to AIIM, advanced capture is involved still only with 10% of existing RPA and almost 25% plan to incorporate it into RPA-based processes.
In the next – and last – article of the series, we will focus on how the data, once extracted, is being sent to downstream applications, moving through business systems and fueling “real” process automation.
[1] See https://rapid.sap.com/bp/#/IRPA_S4HANA
- Zbigniew Smierzchala
Interested to know more about how to leverage AI-enabled data extraction, document classification and analysis to accelerate business processes and enterprise transformation? Contact Moonoia to schedule a workshop, request a demo or speak with someone from our team.
Disclaimer: Opinions or points of view expressed in this article represent the personal position of the author. This document does not constitute professional advice. The information in this document has been obtained or derived from sources believed by the author to be reliable but don’t represent that this information is accurate or complete. Any opinions or estimates contained in this document represent a judgment at this time and are subject to change without notice.