Over the past two years, the field of Artificial Intelligence (AI) has been advancing at an incredible pace. While much attention has been given to large language models like ChatGPT, there have also been considerable advancements in document processing. These advancements have brought us new solutions that deliver impressive improvements in data extraction. We are now entering an era of information extraction, more than data extraction.
This fresh approach introduces three significant improvements:
-
Enhanced extraction performance: These solutions exhibit increased extraction accuracy. Better results, full stop.
-
Reduced computational power requirement: Document processing can be completed faster or cheaper depending on your priorities.
-
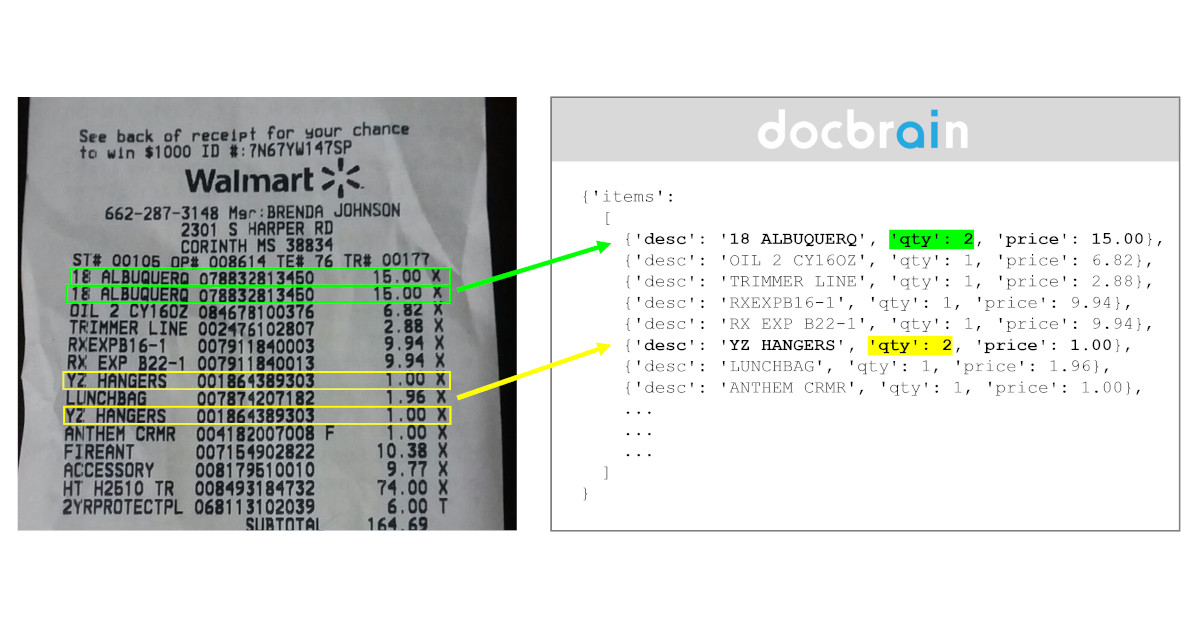
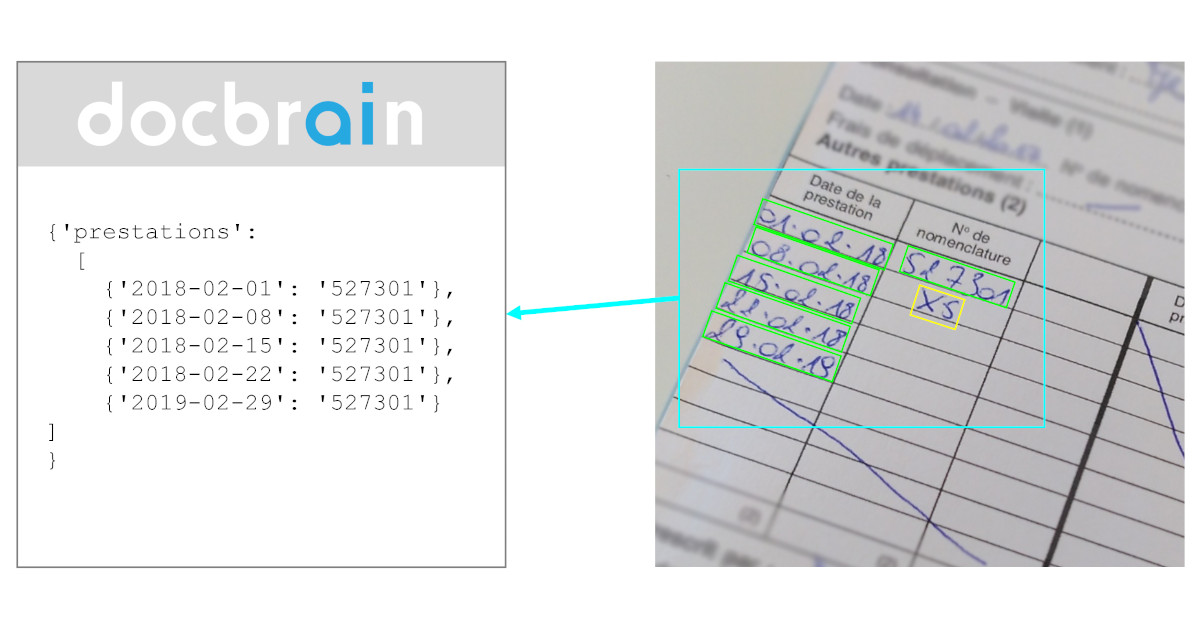
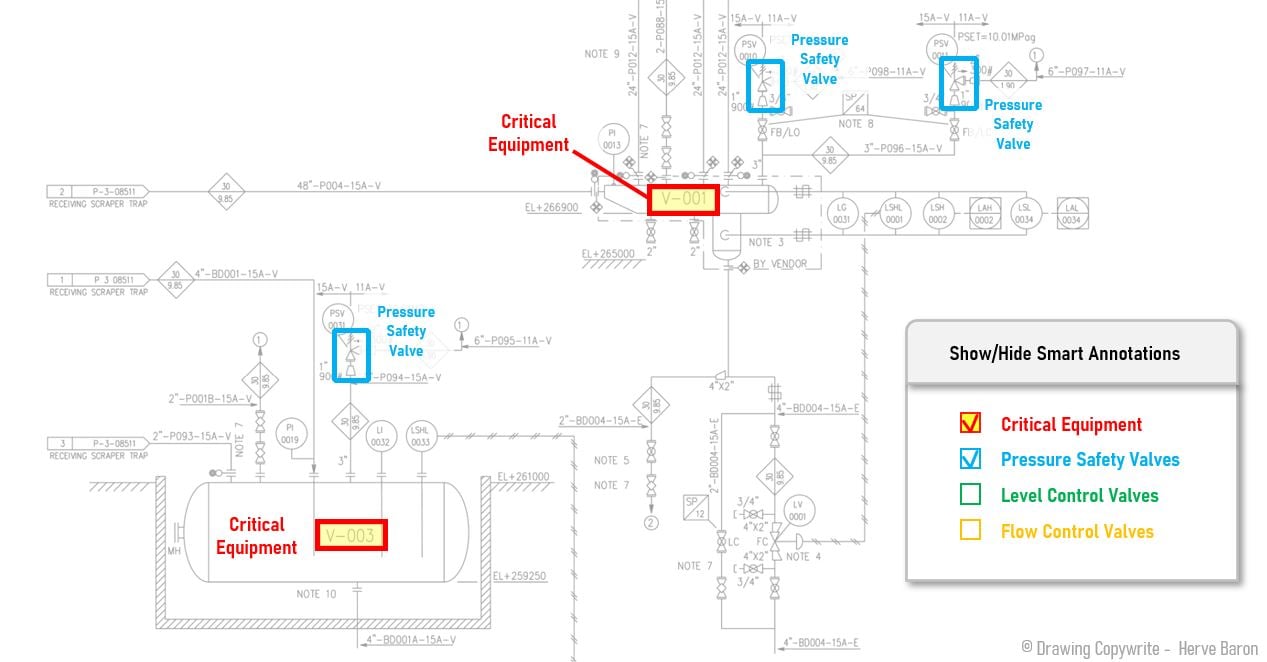
Self-learning capabilities: New solutions can “think” outside the box – with limitations, though – and extract data that may not be explicitly mentioned in the document. This paradigm demonstrates the machine's capacity to come up with derived knowledge.
Do you feel the magic in the air?
Unquestionably, the most exciting improvement lies within this last aspect - a realm where the true magic happens! However, beyond its stunning impact, this breakthrough generates fundamental and transforming changes for the users.
Simpler global processes are made possible, which expedite development, testing, deployment, and maintenance timelines. Compared to legacy solutions that stretched over months for implementation, deployment of these models can now be achieved in days or weeks. In addition, by simplifying workflows, error propagation in the overall process is significantly reduced.
“Show me the money!”
But enough talk. Let's observe these newfound capabilities in action.
In the next series of blog articles, we delve into five real-world examples from our solutions portfolio. Each piece highlights one case study at a time, unveiling the possibilities engendered by this revolutionary technology. Cases have been chosen because they are easy to understand. Even if some may look anecdotic, the impact on the final performance is anything but anecdotic when processing tens or hundreds of thousands of documents.
Select the example that resonates most closely with your use case. Nevertheless, the other featured use cases may also occur in your application. Don't hesitate to read them too.
Use cases selected for analysis are as follows:
If you have any questions about these innovative data extraction solutions or any particular use case detailed in this series, please do not hesitate to contact us.
Enjoy your reading!